

自2016年AIpha GO与李世石围棋大战以来,近两年AI格外火爆,尤其是学术教授组合机器人小游戏,开始转战游戏作为AI算法研究的试验场。 众所周知,游戏行业对 AI 的处理方式通常采用基于规则的行为树或状态机。 这个方法一开始会比较简单,AI写几条规则就可以运行了。 但它也有一个缺点。 当我们想把人工智能的水平提高到一定的层次和阶段时,就会变得非常困难。
这一次,深度学习推动了AI技术革命。 会给我们的游戏行业带来什么好处? 我们内部也一直在思考和探索。 今天主要和大家分享一下我们基于斗地主卡牌游戏的思考和探索。

邓大富讲话
邓大富介绍了人工智能在斗地主卡牌游戏中的背景。 这个AI需要满足三个条件:1.AI等级有一定的高度,比如和人类高手差不多; 2. AI行为应该是类人的,比如当一个玩家离开并主持AI时,其他玩家没有任何感知; 3、AI支撑用户的运营成本不宜过高。 简单来说,在卡牌游戏中,像人类一样玩牌的机器人的分享仅限于经典的三人斗地主玩法。 斗地主卡牌游戏AI也将应用于很多场景,比如托管AI、尽可能匹配AI匹配水平相近的玩家提升用户体验、AI教学等。
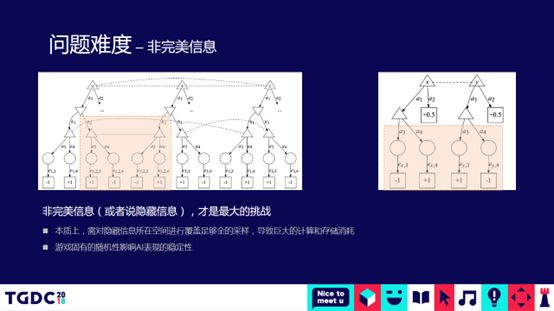
不完全信息的博弈问题是斗地主AI面临的最大挑战
邓大夫提到,棋牌游戏的状态空间非常大。 围棋棋盘的复杂度相当于太阳系的原子数,斗地主的复杂度相当于整个深圳市所含的原子数。 根据董事会进行详尽的列举。 高度智能的人工智能几乎是不可能的。 基本上所有的棋局难题都基本解决了。 围棋的棋盘复杂度是10的170次方,斗地主是10的30次方。 但是,斗地主AI不能简单的使用AIpha zero的技术。 对于棋局来说,牌上的所有信息对双方都是可见的,但是斗地主是看不到其他玩家的牌的。 我们需要对其他两张牌进行各种组合。 经过这样的组合后,棋盘的复杂度会呈指数级急剧上升,学术界称之为不完全信息的博弈问题。 在不完全信息博弈问题研究方面,学界最著名的当属何冷普大师,但博弈固有的随机性影响了AI性能的稳定性。
接下来,邓大富一步步分享了如何搭建斗地主的基本AI流程。 在斗地主AI方面,腾讯拥有海量用户数据、大量高水平玩家的游戏样本,以及大规模的CPU集群和GPU集群。 那么我们可以尝试做监督学习,也就是用模仿学习来解决斗地主卡类。 人工智能问题。
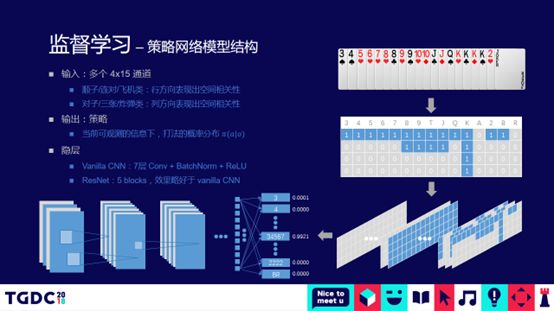
监督学习-策略网络模型结构
首先,使用 CNN 分类模型。 因为CNN有一个特点,一开始主要是做图像处理,提取空间特征的能力和效率会更高。 对于纸牌游戏,我们可以将CNN的通道排列成15张横牌和4张竖牌的矩阵,横牌分别代表组合机器人小游戏,直到小鬼和大鬼,竖牌代表不同的花色。 这样,CNN就可以通过卷积对斗地主规则的Shun、Pair或3 with 2的空间特征进行编码。 这个模型的输出直接就是执行什么样的动作。 斗地主的动作空间会很大,大约有13350种。 在围棋的棋盘上,每一步棋都有 361 种可能。 斗地主会有一万多,因为斗地主有不同的组合。
使用基本模型,您可以进行初步训练。 但是初期的训练效果不是特别理想,包括分类准确和AUC。 因此,邓大夫介绍了斗地主AI的三个优化。
第一类优化涉及对模型的输出进行整理和优化,将原始单一模型拆分为层次模型。 第一层只是识别是否存在这种情况,如果存在则放到第二层模型中进行预测和分类。 在第二层模型中,组合总数会变得比较少,只有一百个级别。
关键特征构建优化实例
在第二次优化中,我们人为地做了一些关键特征。 举个例子,牌有 3 张 3、一对 5、一张 7 和一对 J。 从此卡片中提取特征。 提取的特征的含义是这副牌中是否有三张牌。 如果是三张牌,在CNN的上加一层,给全1。 如果不是,则全为0。 在加入特征抽象之前,概率最高的是一对5。 加上的结果传奇私服沉默版本,3个3加上一对5,排序的时候可以得到更大的概率值。 显然,这个结果更符合人们的预期。
第三个优化是二值化处理,通常在CNN分类中做。 假设有一个取值范围为1234的特征值,此时取3。 事实上,整个CNN通道中有两种表示方法。 第一种表示方法是只使用一个值为 3 的通道; 第二种表示方式是4个通道,第三种表示方式是 1 on the 表示这个值的取值为3。对于卷积运算,二值化处理通常会取得更好的效果。
三大优化提升监督学习整体模型准确率:分层策略模型提升约10%,关键特征构建和二值化处理优化分别提升约5%,模型整体优化性能可达86.2%。 所以,我们用两块GPU卡联合训练,用这个模型训练400万轮的数据(400万轮的游戏数据是随机抽取斗地主玩家水平高的大功率游戏。如果一个人去玩斗地主的话需要不吃不喝不睡玩8-10年才能达到400万回合的规模)。 模型花了大约 8 个小时才收敛到更好的状态。 观战的直观感受是,AI agent的打法和人类几乎没有区别,AI每一步出牌的过程都仿佛经过深思熟虑。 从实际上线测试数据来看,在与人随机匹配时,战斗的胜率超过了人类玩家的平均水平。
但是在监督学习模型的最后阶段,农户的配合偶尔会出现失误,稍微有点经验真人玩家是不会出现这样的失误的。 模仿学习是基于现有的大数据样本,但数据样本不可能是完美的(分析发现在上面提到的人类玩家实际玩游戏过程中提取的400万轮数据中,因为人会犯错,所以会引入很多 that have made),有缺陷的样本导致模仿学习到的AI动作也可能犯错误,这不是学习错误,而是因为不完美样本的引导。 人工过滤样本的成本有点高。 在实际的斗地主过程中,猜出对方牌的准确越高,出牌的等级就越高。 数据分析发现,在斗地主游戏的最后阶段,猜对牌型比猜对牌值更重要,所以确定使用猜牌模型。
加强AI,猜牌模型在游戏最后使用的搜索方式,但这种暴力彻底的搜索,哪怕只剩下两张牌,搜索也大概要跑个几十分钟,一个搜索将对每个后续步骤执行。 这在实践中是行不通的。 因此,我们的树搜索做了三个优化:最终节点只看结果,性能提升了1000倍左右; 缓存节点值,性能提升约100倍; 合法玩法先排序再搜索,性能提升10倍左右。 单CPU核心推理需要几十分钟,缩短到毫秒级,这意味着几十台机器完全可以支撑百万级用户。 邓大富又举了一个例子,在游戏结束时引入了猜牌模型+树搜索AI打牌。

现场讨论
为了更好地模仿人类的打牌,斗地主AI在开局和中盘模仿人类的打牌方式,在末局通过猜牌和推理获得比较大的强化。 之前监督学习中存在的游戏结束错误问题现在完全没有出现。 猜牌模型的测试结果也比较理想,Top3命中准确率可达93.86%。 事实上,在游戏的最后阶段,AI已经接近上帝视角的水平了。
增强型AI结合了猜牌模型和树搜索法,彻底消除了基础AI中的局末协调错误。 树搜索降低了拟人化程度,但可以通过使用策略网络限制候选动作来缓解。 猜牌网络将不完全信息博弈转化为完全信息博弈。 树搜索大大优化了性能。 与冷蒲主法相比,制作过程相对简单,性能高。 仅需50台左右服务器的成本就可以支持所有用户使用AI场景。 每台纯 CPU 机器处理 200/s 请求。 如果你没有大量高质量的游戏副本,有兴趣也可以使用强化学习+MCTS。
公众号编者按:&GOT技术分论坛第三位分享嘉宾邓大富,以斗地主卡牌游戏为例,分享了他在卡牌AI方面的思考与探索。 现场充满了机智和激动。 GOT公众号明天将为大家带来第四期分享嘉宾庞薇薇《手游研发运营2.0——潘多拉解决方案实践》的精彩内容。 感谢您的关注。








